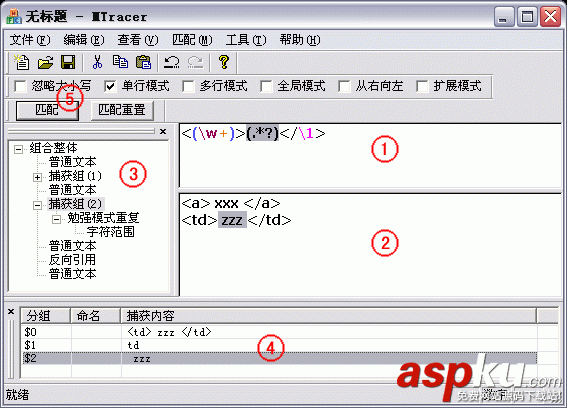
匹配中文字符的正則表達式:
復制代碼代碼如下:
[/u4e00-/u9fa5]
匹配雙字節字符(包括漢字在內):
復制代碼代碼如下:
[^/x00-/xff]
應用:計算字符串的長度(一個雙字節字符長度計2,ASCII字符計1)
復制代碼代碼如下:
String.prototype.len=function(){ return this.replace([^/x00-/xff]/g,"aa").length; }
匹配空行的正則表達式:
復制代碼代碼如下:
/n[/s|]*/r
匹配HTML標記的正則表達式:
復制代碼代碼如下:
/<(.*)>.*<///1>|<(.*) //>/
匹配首尾空格的正則表達式:
復制代碼代碼如下:
(^/s*)|(/s*$)
應用:j avascript中沒有像v bscript那樣的trim函數,我們就可以利用這個表達式來實現,如下:
復制代碼代碼如下:
String.prototype.trim = function()
{
return this.replace(/(^/s*)|(/s*$)/g, "");
}
利用正則表達式分解和轉換IP地址
下面是利用正則表達式匹配IP地址,并將IP地址轉換成對應數值的Javascript程序:
復制代碼代碼如下:
function IP2V(ip)
{
re=/(/d+)/.(/d+)/.(/d+)/.(/d+)/g //匹配IP地址的正則表達式
if(re.test(ip))
{
return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4*1
}
else
{
throw new Error("Not a valid IP address!")
}
}
不過上面的程序如果不用正則表達式,而直接用split函數來分解可能更簡單,程序如下:
復制代碼代碼如下:
var ip="10.100.20.168"
ip=ip.split(".")
alert("IP值是:"+(ip[0]*255*255*255+ip[1]*255*255+ip[2]*255+ip[3]*1))
匹配Email地址的正則表達式:
復制代碼代碼如下:
/w+([-+.]/w+)*@/w+([-.]/w+)*/./w+([-.]/w+)*
匹配網址URL的正則表達式:
復制代碼代碼如下:
http://([/w-]+/.)+[/w-]+(/[/w- ./?%&=]*)?
利用正則表達式去除字串中重復的字符的算法程序:[*注:此程序不正確]
復制代碼代碼如下:
var s="abacabefgeeii"
var s1=s.replace(/(.).*/1/g,"$1")
var re=new RegExp("["+s1+"]","g")
var s2=s.replace(re,"")
alert(s1+s2) //結果為:abcefgi
*注
===============================
如果var s = “abacabefggeeii”
結果就不對了,結果為:abeicfgg
正則表達式的能力有限
===============================
我原來在CSDN上發貼尋求一個表達式來實現去除重復字符的方法,最終沒有找到,這是我能想到的最簡單的實現方法。思路是使用后向引用取出包括重復的字符,再以重復的字符建立第二個表達式,取到不重復的字符,兩者串連。這個方法對于字符順序有要求的字符串可能不適用。
得用正則表達式從URL地址中提取文件名的javascript程序,如下結果為page1
復制代碼代碼如下:
s="http://blog.penner.cn/page1.htm"
s=s.replace(/(.*//){ 0, }([^/.]+).*/ig,"$2")
alert(s)
利用正則表達式限制網頁表單里的文本框輸入內容:
用正則表達式限制只能輸入中文:
復制代碼代碼如下:
onkeyup="value=value.replace(/[^/u4E00-/u9FA5]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/u4E00-/u9FA5]/g,''))"
用正則表達式限制只能輸入全角字符:
復制代碼代碼如下:
onkeyup="value=value.replace(/[^/uFF00-/uFFFF]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/uFF00-/uFFFF]/g,''))"
用正則表達式限制只能輸入數字:
復制代碼代碼如下:
onkeyup="value=value.replace(/[^/d]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/d]/g,''))"
用正則表達式限制只能輸入數字和英文:
復制代碼代碼如下:
onkeyup="value=value.replace(/[/W]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/d]/g,''))"
匹配非負整數(正整數 + 0)
復制代碼代碼如下:
^/d+$
匹配正整數
復制代碼代碼如下:
^[0-9]*[1-9][0-9]*$
匹配非正整數(負整數 + 0)
復制代碼代碼如下:
^((-/d+)|(0+))$
匹配負整數
復制代碼代碼如下:
^-[0-9]*[1-9][0-9]*$
匹配整數
復制代碼代碼如下:
^-?/d+$
匹配非負浮點數(正浮點數 + 0)
復制代碼代碼如下:
^/d+(/./d+)?$
匹配正浮點數
復制代碼代碼如下:
^(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*))$
匹配非正浮點數(負浮點數 + 0)
復制代碼代碼如下:
^((-/d+(/./d+)?)|(0+(/.0+)?))$
匹配負浮點數
復制代碼代碼如下:
^(-(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*)))$
匹配浮點數
復制代碼代碼如下:
^(-?/d+)(/./d+)?$
匹配由26個英文字母組成的字符串
復制代碼代碼如下:
^[A-Za-z]+$
匹配由26個英文字母的大寫組成的字符串
復制代碼代碼如下:
^[A-Z]+$
匹配由26個英文字母的小寫組成的字符串
復制代碼代碼如下:
^[a-z]+$
匹配由數字和26個英文字母組成的字符串
復制代碼代碼如下:
^[A-Za-z0-9]+$
匹配由數字、26個英文字母或者下劃線組成的字符串
復制代碼代碼如下:
^/w+$
匹配email地址
復制代碼代碼如下:
^[/w-]+(/.[/w-]+)*@[/w-]+(/.[/w-]+)+$
匹配url
復制代碼代碼如下:
^[a-zA-z]+://匹配(/w+(-/w+)*)(/.(/w+(-/w+)*))*(/?/S*)?$
匹配html tag
復制代碼代碼如下:
</s*(/S+)(/s[^>]*)?>(.*?)</s*///1/s*>
Visual Basic & C# Regular Expression
1.確認有效電子郵件格式
下面的示例使用靜態 Regex.IsMatch 方法驗證一個字符串是否為有效電子郵件格式。如果字符串包含一個有效的電子郵件地址,則 IsValidEmail 方法返回 true,否則返回 false,但不采取其他任何操作。您可以使用 IsValidEmail,在應用程序將地址存儲在數據庫中或顯示在 ASP.NET 頁中之前,篩選出包含無效字符的電子郵件地址。
[Visual Basic]
復制代碼代碼如下:
Function IsValidEmail(strIn As String) As Boolean
' Return true if strIn is in valid e-mail format.
Return Regex.IsMatch(strIn, ("^([/w-/.]+)@((/[[0-9]{ 1,3 }/.[0-9]{ 1,3 }/.[0-9]{ 1,3 }/.)|(([/w-]+/.)+))([a-zA-Z]{ 2,4 }|[0-9]{ 1,3 })(/]?)$")
End Function
[C#]
復制代碼代碼如下:
bool IsValidEmail(string strIn)
{
// Return true if strIn is in valid e-mail format.
return Regex.IsMatch(strIn, @"^([/w-/.]+)@((/[[0-9]{ 1,3 }/.[0-9]{ 1,3 }/.[0-9]{ 1,3 }/.)|(([/w-]+/.)+))([a-zA-Z]{ 2,4 }|[0-9]{ 1,3 })(/]?)$");
}
2.清理輸入字符串
下面的代碼示例使用靜態 Regex.Replace 方法從字符串中抽出無效字符。您可以使用這里定義的 CleanInput 方法,清除掉在接受用戶輸入的窗體的文本字段中輸入的可能有害的字符。CleanInput 在清除掉除 @、-(連字符)和 .(句點)以外的所有非字母數字字符后返回一個字符串。
[Visual Basic]
復制代碼代碼如下:
Function CleanInput(strIn As String) As String
' Replace invalid characters with empty strings.
Return Regex.Replace(strIn, "[^/w/.@-]", "")
End Function
[C#]
復制代碼代碼如下:
String CleanInput(string strIn)
{
// Replace invalid characters with empty strings.
return Regex.Replace(strIn, @"[^/w/.@-]", "");
}
3.更改日期格式
以下代碼示例使用 Regex.Replace 方法來用 dd-mm-yy 的日期形式代替 mm/dd/yy 的日期形式。
[Visual Basic]
復制代碼代碼如下:
Function MDYToDMY(input As String) As String
Return Regex.Replace(input, _
"/b(?<month>/d{ 1,2 })/(?<day>/d{ 1,2 })/(?<year>/d{ 2,4 })/b", _
"${ day }-${ month }-${ year }")
End Function
[C#]
復制代碼代碼如下:
String MDYToDMY(String input)
{
return Regex.Replace(input,"//b(?<month>//d{ 1,2 })/(?<day>//d{ 1,2 })/(?<year>//d{ 2,4 })//b","${ day }-${ month }-${ year }");
}
Regex 替換模式
本示例說明如何在 Regex.Replace 的替換模式中使用命名的反向引用。其中,替換表達式 ${ day } 插入由 (?…) 組捕獲的子字符串。
有幾種靜態函數使您可以在使用正則表達式操作時無需創建顯式正則表達式對象,而 Regex.Replace 函數正是其中之一。如果您不想保留編譯的正則表達式,這將給您帶來方便
4.提取 URL 信息
以下代碼示例使用 Match.Result 來從 URL 提取協議和端口號。例如,“http://www.penner.cn:8080……將返回“http:8080”。
[Visual Basic]
復制代碼代碼如下:
Function Extension(url As String) As String
Dim r As New Regex("^(?<proto>/w+)://[^/]+?(?<port>:/d+)?/", _
RegexOptions.Compiled)
Return r.Match(url).Result("${ proto }${ port }")
End Function
[C#]
復制代碼代碼如下:
String Extension(String url)
{
Regex r = new Regex(@"^(?<proto>/w+)://[^/]+?(?<port>:/d+)?/",
RegexOptions.Compiled);
return r.Match(url).Result("${ proto }${ port }");
}
只有字母和數字,不小于6位,且數字字母都包含的密碼的正則表達式
在C#中,可以用這個來表示:
復制代碼代碼如下:
"/w{ 6 }(/w+)*"
一個將需要將路徑字符串拆分為根目錄和子目錄兩部分的算法程序,考慮路徑格式有:C:/aa/bb/cc ,//aa/bb/cc , ftp://aa.bb/cc 上述路徑將分別被拆分為:C:/和aa/bb/cc ,//aa 和 /bb/cc , ftp:// 和 aa.bb/cc 用javascript實現如下:
復制代碼代碼如下:
var strRoot,strSub
var regPathParse=/^([^//^//]+[////]+|////[^//]+)(.*)$/
if(regPathParse.test(strFolder))
{
strRoot=RegExp.$1
strSub=RegExp.$2
}