筆記中提供了大量的代碼示例,需要說明的是,大部分代碼示例都是本人所敲代碼并進行測試,不足之處,請大家指正~
LZ 本來想先仔細寫一寫 Hadoop 偽分布式的部署安裝,然后介紹一些 HDFS 的內容再來介紹 MapReduce,是在是沒有抽出空,今天就簡單入門一下 MapReduce 吧。
一、MapReduce 概述
1.MapReduce 是一種分布式計算模型,由Google提出,主要用于搜索領域,解決海量數據的計算問題.
2.MapReduce 由兩個階段組成:Map和Reduce,用戶只需要實現map()和reduce()兩個函數,即可實現分布式計算
二、具體實現
1.先來看一下 Eclipse 中此應用的包結構

2.創建 map 的任務處理類:WCMapper
/* * 1.Mapper 類的四個泛型中,前兩個指定 mapper 輸入數據的類型,后兩個指定 mapper 輸出數據的類型 * KEYIN 是輸入的 key 的類型,VALUEIN 是輸入的 value 的類型 * KEYOUT 是輸出的 key 的類型,VALUEOUT 是輸出的 value 的類型 * 2.map 和 reduce 的數據的輸入輸出都是以 key-value 對的形式封裝的 * 3.默認情況下,框架傳遞給我們的 mapper 的輸入數據中,key 是要處理的文本中一行的起始偏移量,為 Long 類型, * 這一行的內容為 value,為 String 類型的 * 4.后兩個泛型的賦值需要我們結合實際情況 * 5.為了在網絡中傳輸時序列化更高效,Hadoop 把 Java 中的 Long 封裝為 LongWritable, 把 String 封裝為 Text */public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> { //重寫 Mapper 中的 map 方法,MapReduce 框架每讀一行數據就調用一次此方法 @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //書寫具體的業務邏輯,業務要處理的數據已經被框架傳遞進來,就是方法的參數中的 key 和 value //key 是這一行數據的起始偏移量,value 是這一行的文本內容 //1.將 Text 類型的一行的內容轉為 String 類型 String line = value.toString(); //2.使用 StringUtils 以空格切分字符串,返回 String[] String[] words = StringUtils.split(line, " "); //3.循環遍歷 String[],調用 context 的 writer()方法,輸出為 key-value 對的形式 //key:單詞 value:1 for(String word : words) { context.write(new Text(word), new LongWritable(1)); } }}2.創建 reduce 的任務處理類:WCReducer:
/* * 1.Reducer 類的四個泛型中,前兩個輸入要與 Mapper 的輸出相對應。輸出需要聯系具體情況自定義 */public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> { //框架在 map 處理完之后,將所有的 kv 對緩存起來,進行分組,然后傳遞一個分組(<key,{values}>,例如:<"hello",{1,1,1,1}>), //調用此方法 @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context)throws IOException, InterruptedException { //1.定義一個計數器 long count = 0; //2.遍歷 values的 list,進行累加求和 for(LongWritable value : values) { //使用 LongWritable 的 get() 方法,可以將 一個 LongWritable 類型轉為 Long 類型 count += value.get(); } //3.輸出這一個單詞的統計結果 context.write(key, new LongWritable(count)); }}3.創建一個類,用來描述一個特定的作業:WCRunner,(此類了LZ沒有按照規范的模式寫)
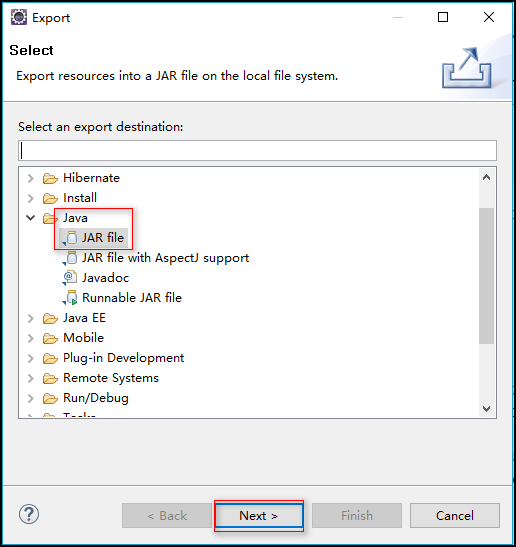
/** * 此類用來描述一個特定的作業 * 例:1.該作業使用哪個類作為邏輯處理中的 map,哪個作為 reduce * 2.指定該作業要處理的數據所在的路徑 * 3.指定該作業輸出的結果放到哪個路徑 */public class WCRunner { public static void main(String[] args) throws Exception { //1.獲取 Job 對象:使用 Job 靜態的 getInstance() 方法,傳入 Configuration 對象 Configuration conf = new Configuration(); Job wcJob = Job.getInstance(conf); //2.設置整個 Job 所用的類的 jar 包:使用 Job 的 setJarByClass(),一般傳入 當前類.class wcJob.setJarByClass(WCRunner.class); //3.設置本 Job 使用的 mapper 和 reducer 的類 wcJob.setMapperClass(WCMapper.class); wcJob.setReducerClass(WCReducer.class); //4.指定 reducer 輸出數據的 kv 類型 注:若 mapper 和 reducer 的輸出數據的 kv 類型一致,可以用如下兩行代碼設置 wcJob.setOutputKeyClass(Text.class); wcJob.setOutputValueClass(LongWritable.class); //5.指定 mapper 輸出數據的 kv 類型 wcJob.setMapOutputKeyClass(Text.class); wcJob.setMapOutputValueClass(LongWritable.class); //6.指定原始的輸入數據存放路徑:使用 FileInputFormat 的 setInputPaths() 方法 FileInputFormat.setInputPaths(wcJob, new Path("/wc/srcdata/")); //7.指定處理結果的存放路徑:使用 FileOutputFormat 的 setOutputFormat() 方法 FileOutputFormat.setOutputPath(wcJob, new Path("/wc/output/")); //8.將 Job 提交給集群運行,參數為 true 表示顯示運行狀態 wcJob.waitForCompletion(true); }}4.將此項目導出為 jar 文件
步驟:右擊項目 ---> Export ---> Java ---> JAR file --->指定導出路徑(我指定的為:e:/wc.jar) ---> Finish
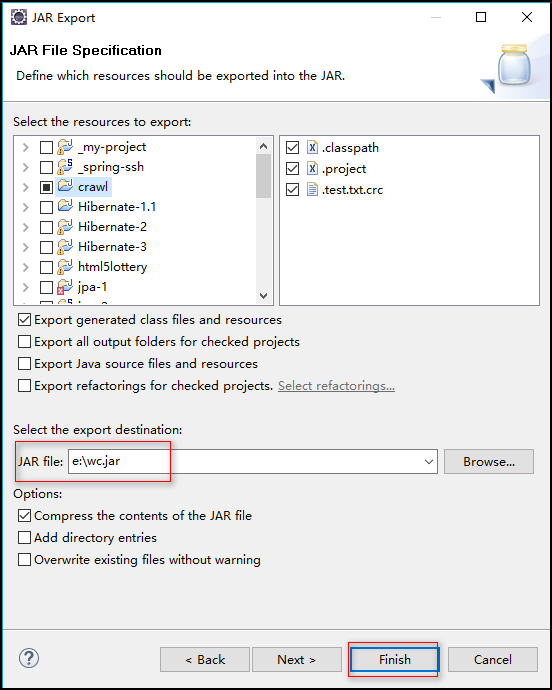
5.將導出的 jar 包上傳到 linux 上
LZ使用的方法是:在 SecureCRT 客戶端中使用 Alt + p 快捷鍵打開上傳文件的終端,輸入 put e"/wc.jar 即可上傳

6.創建初始測試文件:words.log
命令: vi words.log 自己輸入測試數據即可

7.在 hdfs 中創建存放初始測試文件 words.log 的目錄:我們在 WCRunner 中指定的是 /wc/srcdata/
命令:
[hadoop@crawl ~]$ hadoop fs -mkdir /wc
[hadoop@crawl ~]$ hadoop fs -mkdir /wc/srcdata
8.將初始測試文件 words.log 上傳到 hdfs 的相應目錄
命令:[hadoop@crawl ~]$ hadoop fs -put words.log /wc/srcdata
9.運行 jar 文件
命令:hadoop jar wc.jar com.software.hadoop.mr.wordcount.WCRunner
此命令為 hadoop jar wc.jar 加上 WCRunner類的全類名,程序的入口為 WCRunner 內的 main 方法,運行完此命令便可以看到輸出日志信息:

然后前去我們之前配置的存放輸出結果的路徑(LZ之前設置的為:/wc/output/)就可以看到 MapReduce 的執行結果了
輸入命令:hadoop fs -ls /wc/output/ 查看以下 /wc/output/ 路徑下的內容

結果數據就在第二個文件中,輸入命令:hadoop fs -cat /wc/output/part-r-00000 即可查看:
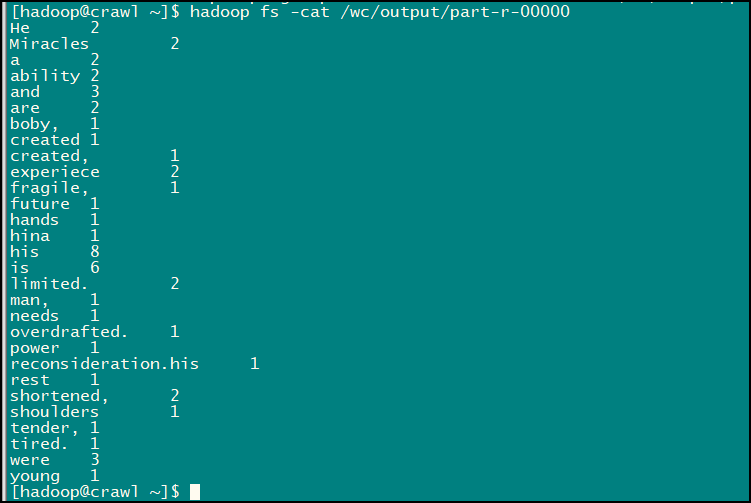
至此我們的這個小應用就完成了,是不是很有意思的,LZ 在實現的時候還是發生了一點小意外:
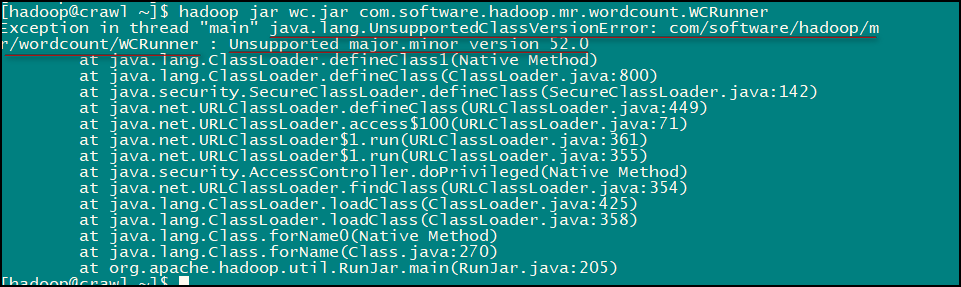
LZ 查閱資料發現這是由于 jdk 版本不一致導致的錯誤,統一 jdk 版本后便沒有問題了。
以上這篇MapReduce 入門之一步步自實現詞頻統計功能的教程就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持武林網。
新聞熱點






疑難解答
圖片精選