1.問題
最近在做項目的時候碰到一個對mongoDB的數據處理,從MongoDB中拿到內嵌文檔的時間排序的list。
一開始考慮到直接對mongoDB中的屬性排序,后面發現屬性存在內嵌文檔中,所以處理中需要用到聚合函數。
思考
(key)解決這個問題的過程讓我學到很多,發現自己在解決一個問題不僅查找問題的姿勢不對,浪費太多時間。而且在碰到問題之后,應該多看看解決辦法,甚至解決了之后要去思考問題,回顧問題。而不是像以前一樣,解決問題了就萬事大吉,拋之腦后。
2.解決
需要對document中的一個tweet_list 集合中的一個屬性 timestamp_ms進行排序。 組內排序
使用聚合框架,通過match,unwind,sort等不同的組件創建一個管道。
類似mysql中的多層嵌套子查詢。
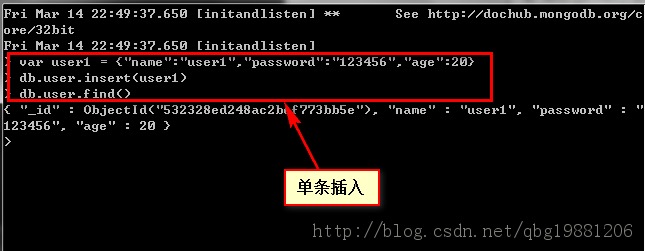
mongoDB中js代碼
db.text.aggregate( // Initial document match (uses index, if a suitable one is available) [ { $match: { _id : ObjectId("5ca95b4bfb60ec43b5dd0db5") }}, // Expand the scores array into a stream of documents { $unwind: '$tweet_list' }, { $match: { 'tweet_list.timestamp_ms': '1451841845660' }}, // Sort in descending order { $sort: { 'tweet_list.timestamp_ms': 1 }} ])java實現此聚合函數
java中的Aggregation類,查詢條件的順序決定結果。
Aggregation agg = Aggregation.newAggregation( Aggregation.match(Criteria.where("_id").is(id)), Aggregation.unwind("tweet_list"), Aggregation.sort(Sort.Direction.ASC,"tweet_list.timestamp_ms"), Aggregation.project("tweet_list.timestamp_ms","tweet_list.text","tweet_list.created_at"));AggregationResults<JSONObject> results = mongoTemplate.aggregate(agg, "text", JSONObject.class);//System.out.println("results"+results.getRawResults()); //獲取到的結果是document//String res = results.getRawResults();String json = com.mongodb.util.JSON.serialize(results.getRawResults());System.out.println("JSON serialized Document: " + json);JSONObject jso= JSON.parseObject(json);JSONArray resultss=jso.getJSONArray("results");System.out.println(resultss);3.擴展
管道pipeline
以下的管道操作符可以按照任意順序組合在一起使用。每個操作符都會接受一連串文檔,對這些文檔做了類型轉換后,將轉換后的文檔作為結果傳遞給下一個操作符。直到最后一個管道操作符,將結果返回給客戶端。
篩選match
盡可能將帥選放在管道的前部。兩個原因:
1.先過濾掉不需要的文檔,減少管道的工作量。
2.如果在project和group之前執行match,查詢可以用索引。
3.不能在match中使用地理空間操作符
投射project
類似select操作。可以用管道表達式,數學表達式,日期表達式,字符表達式,邏輯表達式等。
分組group
跟mysql中的分組比較像
排序sort
1 升序 -1 降序
限制limit
限制結果條數
跳過skip
丟棄結果中的前n個文檔
拆分unwind
把數組中的每個值拆分為單獨的文檔,例如此問題中需要對一個document中的tweetlist進行排序,可以使用unwind把tweetlist中的不同map拆分成不同的文檔。
結果返回
文檔

MapReduce
如果聚合框架中查詢語言不能不表達,需要用到MapReduce。
使用:把問題拆分為多個小問題,把各個小問題發送到不同的機器上,每臺機器只負責完成一部分的工作,完成之后,再把零碎的解決方案合并。
步驟:
1.映射map:把操作映射到集合中每個文檔
2.洗牌shuffle:按照鍵值分組,并將產生的鍵值組成列表放到對應的鍵中。
3.化簡reduce:把列表中的值化簡成一個單值,值被返回,繼續shuffle,然后最終每個鍵的列表只有一個值,即最終結果,
應用:
1.找到集合中所有鍵
2.網頁分類
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,謝謝大家對武林網的支持。
新聞熱點




疑難解答