盡管NoSQL運動并沒有給分布式數據處理帶來根本性的技術變革,但是依然引發了鋪天蓋地的關于各種協議和算法的研究以及實踐。在這篇文章里,我將針對NoSQL數據庫的分布式特點進行一些系統化的描述。
系統的可擴展性是推動NoSQL運動發展的的主要理由,包含了分布式系統協調,故障轉移,資源管理和許多其他特性。這么講使得NoSQL聽起來像是一個大筐,什么都能塞進去。盡管NoSQL運動并沒有給分布式數據處理帶來根本性的技術變革,但是依然引發了鋪天蓋地的關于各種協議和算法的研究以及實踐。正是通過這些嘗試逐漸總結出了一些行之有效的數據庫構建方法。在這篇文章里,我將針對NoSQL數據庫的分布式特點進行一些系統化的描述。
接下來我們將研究一些分布式策略,比如故障檢測中的復制,這些策略用黑體字標出,被分為三段:
1、數據一致性。NoSQL需要在分布式系統的一致性,容錯性和性能,低延遲及高可用之間作出權衡,一般來說,數據一致性是一個必選項,所以這一節主要是關于數據復制和數據恢復。
2、數據放置。一個數據庫產品應該能夠應對不同的數據分布,集群拓撲和硬件配置。在這一節我們將討論如何分布以及調整數據分布才能夠能夠及時解決故障,提供持久化保證,高效查詢和保證集群中的資源(如內存和硬盤空間)得到均衡使用。
3、對等系統。像 leader election 這樣的的技術已經被用于多個數據庫產品以實現容錯和數據強一致性。然而,即使是分散的的數據庫(無中心)也要跟蹤它們的全局狀態,檢測故障和拓撲變化。這一節將介紹幾種使系統保持一致狀態的技術。
數據一致性
眾所周知,分布式系統經常會遇到網絡隔離或是延遲的情況,在這種情況下隔離的部分是不可用的,因此要保持高可用性而不犧牲一致性是不可能的。這一事實通常被稱作“CAP理論”。然而,一致性在分布式系統中是一個非常昂貴的東西,所以經常需要在這上面做一些讓步,不只是針對可用性,還有多種權衡。為了研究這些權衡,我們注意到分布式系統的一致性問題是由數據隔離和復制引起的,所以我們將從研究復制的特點開始:
現在讓我們仔細看看常用的復制技術,并按照描述的特點給他們分一下類。第一幅圖描繪了不同技術之間的邏輯關系和不同技術在系統的一致性、擴展性、可用性、延遲性之間的權衡坐標。 第二張圖詳細描繪了每個技術。
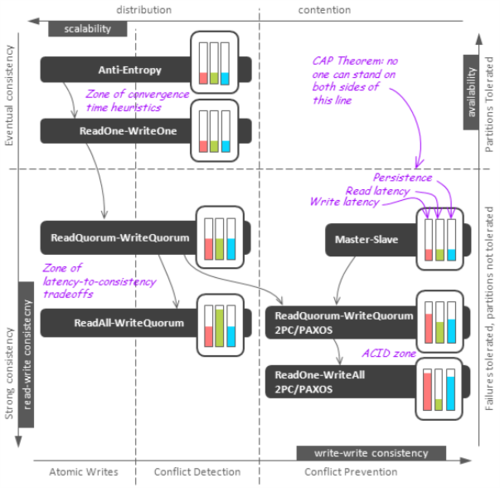
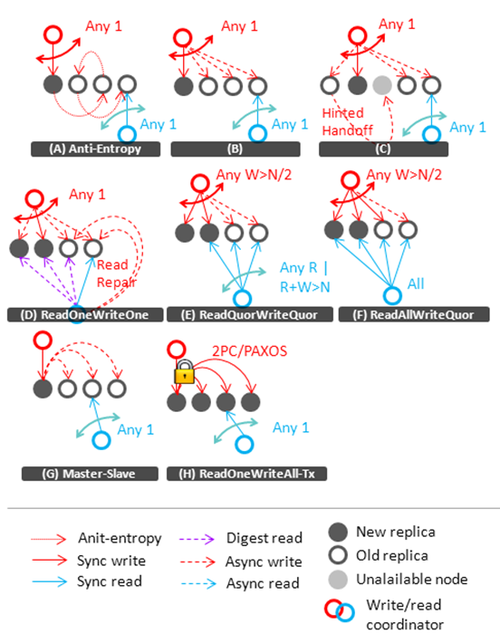
復本因子是4。讀寫協調者可以是一個外部客戶端或是一個內部代理節點。
我們會依據一致性從弱到強把所有的技術過一遍:
(A, 反熵) 一致性最弱,基于策略如下。寫操作的時候選擇任意一個節點更新,在讀的時候如果新數據還沒有通過后臺的反熵協議傳遞到讀的那個節點,那么讀到的仍然是舊數據。(下一節會詳細介紹反熵協議)。這種方法的主要特點是:
- 過高的傳播延遲使它在數據同步方面不太好用,所以比較典型的用法是只作為輔助性的功能來檢測和修復計劃外的不一致。Cassandra就使用了反熵算法來在各節點之間傳遞數據庫拓撲和其他一些元數據信息。
- 一致性保證較弱:即使在沒有發生故障的情況下,也會出現寫沖突與讀寫不一致。
- 在網絡隔離下的高可用和健壯性。用異步的批處理替代了逐個更新,這使得性能表現優異。
- 持久性保障較弱因為新的數據最初只有單個副本。
(B) 對上面模式的一個改進是在任意一個節點收到更新數據請求的同時異步的發送更新給所有可用節點。這也被認為是定向的反熵。
- 與純粹的反熵相比,這種做法只用一點小小的性能犧牲就極大地提高了一致性。然而,正式一致性和持久性保持不變。
- 假如某些節點因為網絡故障或是節點失效在當時是不可用的,更新最終也會通過反熵傳播過程來傳遞到該節點。
(C) 在前一個模式中,使用提示移交技術可以更好地處理某個節點的操作失敗。對于失效節點的預期更新被記錄在額外的代理節點上,并且標明一旦特點節點可用就要將更新傳遞給該節點。這樣做提高了一致性,降低了復制收斂時間。
(D, 一次性讀寫)因為提示移交的責任節點也有可能在將更新傳遞出去之前就已經失效,在這種情況下就有必要通過所謂的讀修復來保證一致性。每個讀操作都會啟動一個異步過程,向存儲這條數據的所有節點請求一份數據摘要(像簽名或者hash),如果發現各節點返回的摘要不一致則統一各節點上的數據版本。我們用一次性讀寫來命名組合了A、B、C、D的技術- 他們都沒有提供嚴格的一致性保證,但是作為一個自備的方法已經可以用于實踐了。
(E, 讀若干寫若干) 上面的策略是降低了復制收斂時間的啟發式增強。為了保證更強的一致性,必須犧牲可用性來保證一定的讀寫重疊。 通常的做法是同時寫入W個副本而不是一個,讀的時候也要讀R個副本。
- 首先,可以配置寫副本數W>1。
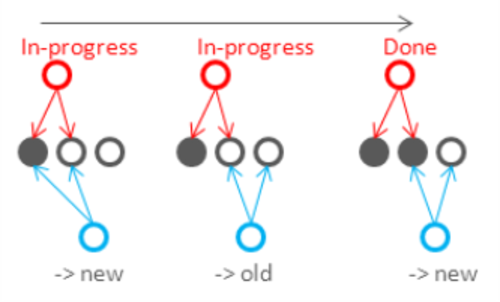
- 其次,因為R+W>N,寫入的節點和讀取的節點之間必然會有重疊,所以讀取的多個數據副本里至少會有一個是比較新的數據(上面的圖中 W=2, R=3, N=4 )。這樣在讀寫請求依序進行的時候(寫執行完再讀)能夠保證一致性(對于單個用戶的讀寫一致性),但是不能保障全局的讀一致性。用下面圖示里的例子來看,R=2,W=2,N=3,因為寫操作對于兩個副本的更新是非事務的,在更新沒有完成的時候讀就可能讀到兩個都是舊值或者一新一舊:
(F, 讀全部寫若干)讀一致性問題可以通過在讀數據的時候訪問所有副本(讀數據或者檢查摘要)來減輕。這確保了只要有至少一個節點上的數據更新新的數據就能被讀取者看到。但是在網絡隔離的情況下這種保證就不能起到作用了。
(G, 主從) 這種技術常被用來提供原子寫或者 沖突檢測持久級別的讀改寫。為了實現沖突預防級別,必須要用一種集中管理方式或者是鎖。最簡單的策略是用主從異步復制。對于特定數據項的寫操作全部被路由到一個中心節點,并在上面順序執行。這種情況下主節點會成為瓶頸,所以必須要將數據劃分成一個個獨立的片區(不同片有不同的master),這樣才能提供擴展性。
(H, Transactional Read Quorum Write Quorum and Read One Write All) 更新多個副本的方法可以通過使用事務控制技術來避免寫沖突。 眾所周知的方法是使用兩階段提交協議。但兩階段提交并不是完全可靠的,因為協調者失效可能會造成資源阻塞。 PAXOS提交協議是更可靠的選擇,但會損失一點性能。 在這個基礎上再向前一小步就是讀一個副本寫所有副本,這種方法把所有副本的更新放在一個事務中,它提供了強容錯一致性但會損失掉一些性能和可用性。
讓我們從以下場景開始:
有許多節點,每條數據會在其中的若干的節點上面存有副本。每個節點都可以單獨處理更新請求,每個節點定期和其他節點同步狀態,如此一段時間之后所有的副本都會趨向一致。同步過程是怎樣進行的?同步何時開始?怎樣選擇同步的對象?怎么交換數據?我們假定兩個節點總是用較新版本的數據覆蓋舊的數據或者兩個版本都保留以待應用層處理。
這個問題常見于數據一致性維護和集群狀態同步(如集群成員信息傳播)等場景。雖然引入一個監控數據庫并制定同步計劃的協調者可以解決這個問題,但是去中心化的數據庫能夠提供更好的容錯性。去中心化的主要做法是利用精心設計的傳染協議,這種協議相對簡單,但是提供了很好的收斂時間,而且能夠容忍任何節點的失效和網絡隔離。盡管有許多類型的傳染算法,我們只關注反熵協議,因為NoSQL數據庫都在使用它。
反熵協議假定同步會按照一個固定進度表執行,每個節點定期隨機或是按照某種規則選擇另外一個節點交換數據,消除差異。有三種反風格的反熵協議:推,拉和混合。推協議的原理是簡單選取一個隨機節點然后把數據狀態發送過去。在真實應用中將全部數據都推送出去顯然是愚蠢的,所以節點一般按照下圖所示的方式工作。
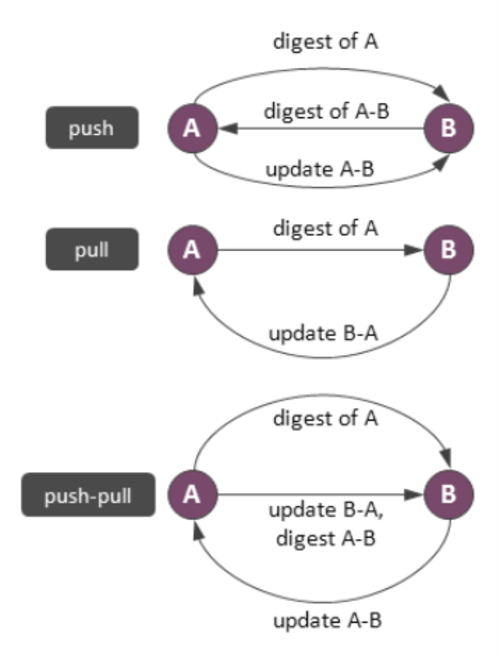
節點A作為同步發起者準備好一份數據摘要,里面包含了A上數據的指紋。節點B接收到摘要之后將摘要中的數據與本地數據進行比較,并將數據差異做成一份摘要返回給A。最后,A發送一個更新給B,B再更新數據。拉方式和混合方式的協議與此類似,就如上圖所示的。
反熵協議提供了足夠好的收斂時間和擴展性。下圖展示了一個在100個節點的集群中傳播一個更新的模擬結果。在每次迭代中,每個節點只與一個隨機選取的對等節點發生聯系。
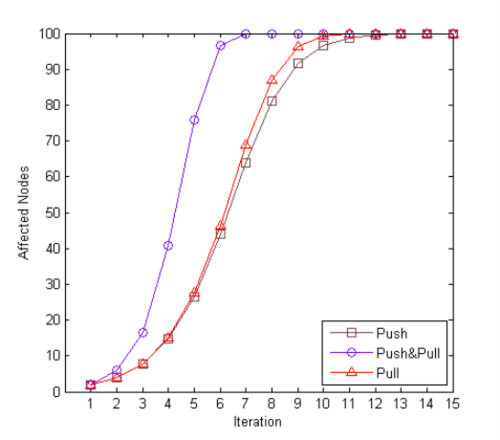
可以看到,拉方式的收斂性比推方式更好,這可以從理論上得到證明。而且推方式還存在一個“收斂尾巴”的問題。在多次迭代之后,盡管幾乎遍歷到了所有的節點,但還是有很少的一部分沒受到影響。與單純的推和拉方式相比, 混合方式的效率更高,所以實際應用中通常使用這種方式。反熵是可擴展的,因為平均轉換時間以集群規模的對數函數形式增長。
盡管這些技術看起來很簡單,仍然有許多研究關注于不同約束條件下反熵協議的性能表現。其中之一通過一種更有效的結構使用網絡拓撲來取代隨機選取 。在網絡帶寬有限的條件下調整傳輸率或使用先進的規則來選取要同步的數據 。摘要計算也面臨挑戰,數據庫會維護一份最近更新的日志以有助于摘要計算。
最終一致數據類型Eventually Consistent Data Types
在上一節我們假定兩個節點總是合并他們的數據版本。但要解決更新沖突并不容易,讓所有副本都最終達到一個語義上正確的值出乎意料的難。一個眾所周知的例子是Amazon Dynamo數據庫中已經刪除的條目可以重現。
我們假設一個例子來說明這個問題:數據庫維護一個邏輯上的全局計數器,每個節點可以增加或者減少計數。雖然每個節點可以在本地維護一個自己的值,但這些本地計數卻不能通過簡單的加減來合并。假設這樣一個例子:有三個節點A、B和C,每個節點執行了一次加操作。如果A從B獲得一個值,并且加到本地副本上,然后C從B獲得值,然后C再從A獲得值,那么C最后的值是4,而這是錯誤的。解決這個問題的方法是用一個類似于向量時鐘的數據結構為每個節點維護一對計數器:
class Counter { int[] plus int[] minus int NODE_ID increment() { plus[NODE_ID]++ } decrement() { minus[NODE_ID]++ } get() { return sum(plus)
主站蜘蛛池模板:
国产精品美女久久久久aⅴ国产馆
|
精品欧美一区二区三区精品久久
|
色免费在线观看
|
日韩在线
|
久久99久久98精品免观看软件
|
国产精品毛片
|
午夜在线视频
|
日韩一区二区观看
|
最新日韩av
|
最近韩国日本免费高清观看
|
一区二区三区精品视频
|
色婷婷综合久久久
|
国产成人高清视频
|
国产乱码精品一品二品
|
www.久久久久|
操人网
|
亚洲日本欧美日韩高观看
|
超碰激情|
99视频精品
|
欧美精品一区二区三区在线
|
99久久99|
成年人网站在线免费观看
|
亚洲一区二区三区免费在线
|
99国产精品久久久久久久
|
在线国产视频
|
日韩成人精品视频
|
伊人福利视频
|
综合一区二区三区
|
久久综合久色欧美综合狠狠
|
国产精品久久久久久久
|
欧洲尺码日本国产精品
|
亚洲精品在线免费观看视频
|
亚洲高清av在线
|
亚洲一区日本
|
激情欧美日韩一区二区
|
av一二三区
|
欧美日韩亚洲国产综合
|
日韩精品1区2区3区
99久久视频
|
精品日韩一区
|
99视频免费
|
青楼18春一级毛片
|