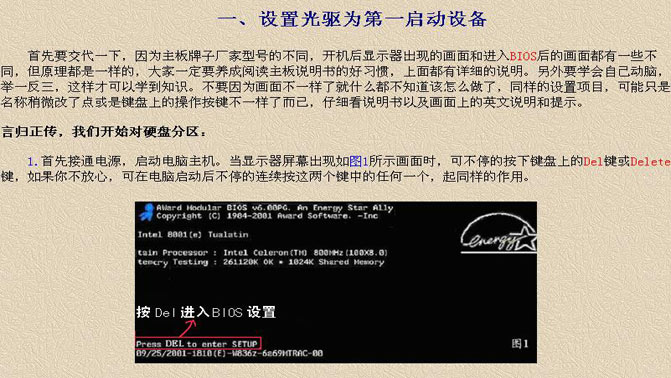
以下是DNA序列,存儲(chǔ)在window下F:/perl/data.txt里面:
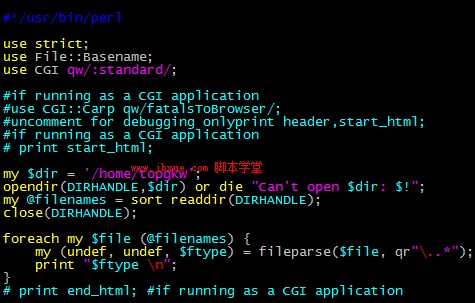
下面是程序:
#首先定義四種堿基的數(shù)量為0
$count_A=0;
$count_T=0;
$count_C=0;
$count_G=0;
#首先要先把序列進(jìn)行合并成一行
#先確定所要處理的文件的路徑及文件名(在windows系統(tǒng)下面要按照這樣的例子寫
#f://perl//data.txt
print "please input the Path just like this f:////perl////data.txt/n";
chomp($dna_filename=<STDIN>);
#打開文件
open(DNAFILENAME,$dna_filename)||die("can not open the file!");
#將文件賦予一個(gè)數(shù)組
@DNA=<DNAFILENAME>;
#以下兩步要把所有的行合并成一行,然后去掉所有的空白符
$DNA=join('',@DNA);
$DNA=~s//s//g;
#將DNA分解成,然后賦值到數(shù)組
@DNA=split('',$DNA);
#然后依次讀取數(shù)組的元素,并對(duì)四種堿基的數(shù)量進(jìn)行統(tǒng)計(jì)
foreach $base(@DNA)
{
if ($base eq 'A')
{
$count_A=$count_A+1;
}
elsif ($base eq 'T')
{
$count_T=$count_T+1;
}
elsif ($base eq 'C')
{
$count_C=$count_C+1;
}
elsif ($base eq 'G')
{
$count_G=$count_G+1;
}
else
{
print "error/n"
}
}
#輸出最后的結(jié)果
print "A=$count_A/n";
print "T=$count_T/n";
print "C=$count_C/n";
print "G=$count_G/n";
F:/>
大家仔細(xì)看一看最上面的原始 DNA序列,用特殊顏色標(biāo)記的,可以看到有一個(gè)V,所以會(huì)輸出錯(cuò)誤。
這里把DNA序列經(jīng)過整合成一行,然后去除所有的空白字符以后,又把$DNA通過split函數(shù)變成了數(shù)組,然后進(jìn)行統(tǒng)計(jì),那有沒有更好的辦法呢?
其實(shí)perl里有一個(gè)函數(shù),substr。
我們先來看一看這個(gè)函數(shù)的用法,substr是針對(duì)一個(gè)大字符串的操作符(The substr function works with only a part of a larger string )言外之意就是對(duì)一個(gè)很長(zhǎng)的字符串,進(jìn)行片段化處理,取其中的一部分。我們這里用到的就是這個(gè)特性。
$little_string =substr($large_string,$start_position,$length)
$小片段=substr($大片段,$你要截取的小片段的起始位置,$你要截取的長(zhǎng)度)
我們這里為了統(tǒng)計(jì)DNA中各種堿基的數(shù)量,所以要處理的字符串是一個(gè)堿基,所以我們要把$length設(shè)置為1。這樣才能夠滿足我們的需求。
下面我們把修改過的代碼寫下:
#首先定義四種堿基的數(shù)量為0
$count_A=0;
$count_T=0;
$count_C=0;
$count_G=0;
#首先要先把序列進(jìn)行合并成一行
#先確定所要處理的文件的路徑及文件名(在windows系統(tǒng)下面要按照這樣的例子寫
#f://perl//data.txt
print "please input the Path just like this f:////perl////data.txt/n";
chomp($dna_filename=<STDIN>);
#打開文件
open(DNAFILENAME,$dna_filename)||die("can not open the file!");
#將文件賦予一個(gè)數(shù)組
@DNA=<DNAFILENAME>;
#以下兩步要把所有的行合并成一行,然后去掉所有的空白符
$DNA=join('',@DNA);
$DNA=~s//s//g;
#然后依次讀取字符串的元素,并對(duì)四種堿基的數(shù)量進(jìn)行統(tǒng)計(jì)
for ($position=0;$position<length $DNA;++$position)
{
$base=substr($DNA,$position,1);
if ($base eq 'A')
{
$count_A=$count_A+1;
}
elsif ($base eq 'T')
{
$count_T=$count_T+1;
}
elsif ($base eq 'C')
{
$count_C=$count_C+1;
}
elsif ($base eq 'G')
{
$count_G=$count_G+1;
}
else
{
print "error/n"
}
}
#輸出最后的結(jié)果
print "A=$count_A/n";
print "T=$count_T/n";
print "C=$count_C/n";
print "G=$count_G/n";
得到的結(jié)果如下:
F:/>
新聞熱點(diǎn)




疑難解答
圖片精選