關鍵詞:term, token, index, mapping index,mapping是理解ela原理的兩個關鍵概念。
首先,我們可以在kibana或curl命令行方式任意輸入關鍵字進行全文檢索是基于ela內部對信息存儲的方式。一種稱為倒排索引的方式(網上很多介紹這個概念,一看就懂)。了解了它又自然而然明白了文本的詞、句在被索引前需要經過合適方式的處理。 elasticsearch對詞句的分析(三個過程組合而成) character filter(字符過濾:去除無用標記html) tokenizer(分詞器:根據分隔符斷詞) token filter(表征過濾:轉換小寫,去詞,增加詞) 內建分析器: 標準分析器 簡單分析器 空格分析器 語言分析器
當我們索引一個文檔時,全文字段會被分析為單獨的詞用以創建倒排索引。當我們在全文字段搜索時,也要讓查詢字符串經過同樣的分析流程處理,確保這些詞在索引中存在。
就是說,原文經過分析后以合適的語法語言形式(比如大寫變小寫,復數變單數)保存。而我們進行查詢時的輸入也需要經過這樣的轉換才能匹配。 為了保證document的每個字段field都能以正確的格式存儲索引,這就需要在創建索引時通過mapping定義,來規定不同字段的格式類型,如何被索引等。
當Elasticsearch 在你的文檔中探測到一個新的字符串字段,它將自動設置它為全文string字段并用standard分析器分析。 也許我們想要一個更適合這個數據的語言分析器。或者不做任何分析,只存儲確切值。為了達到這種效果,必須通過mapping人工設置這些字段。
“index參數控制字符串以何種方式被索引 analyzed: 分析并索引,會導致分詞,大小寫等變化 not_analyzed: 索引,但不分析,內容和指定值完全一致 no:不索引, 不會被搜索到 類型說明 根據官方文檔
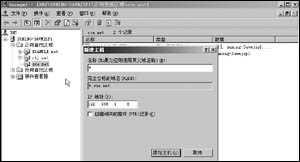
PUT /gb{ "mappings": { "tweet": { # <-- tweet對應 type "PRoperties": { "tweet": { # <-- 對應具體的字段名(下面包含三個參數名type, index, analyzer) "type": "string", ## string類型默認index值為analyzed "analyzer": "english" ## 指明使用英語分析器 }, "date": { "type": "date" }, "name": { "type": "string" }, "user_id": { "type": "long" } } } }}新聞熱點





疑難解答