PDF掃描件都是由圖片組成的,文字是無法直接復制,想要制作一個雙層pdf文件,有圖片,還可以直接復制文字,該怎么實現呢?我們可以通過使用Acrobat軟件,我們可以使用軟件所帶的OCR識別工具,為PDF文檔增加一層透明文字層,從而制作出雙層PDF。使得PDF看起來是掃描件,但可以直接復制文字,下面我們就來看看詳細的教程。
1、下面是掃描生成的PDF文檔,可以看出,文字是無法直接復制的。
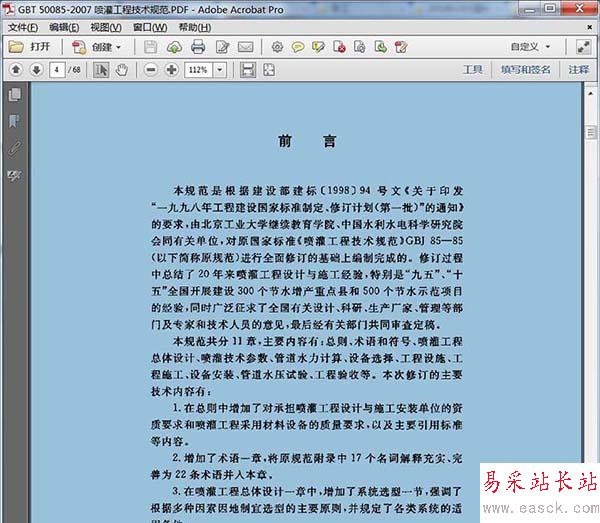
2、點擊Acrobat軟件工具欄右上角的“工具”選項,打開“文本識別“,然后點擊“在本文件中”。
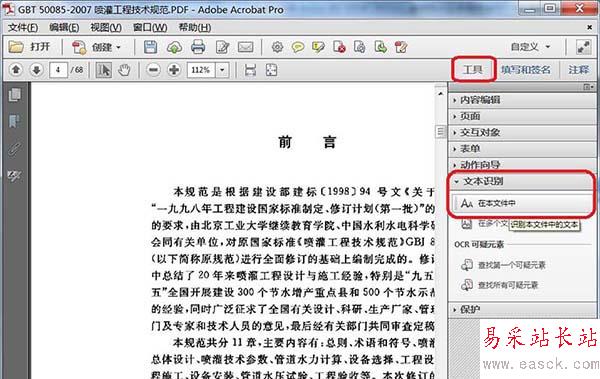
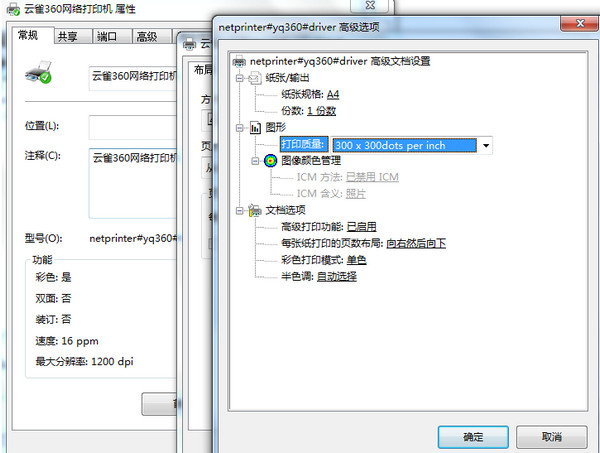
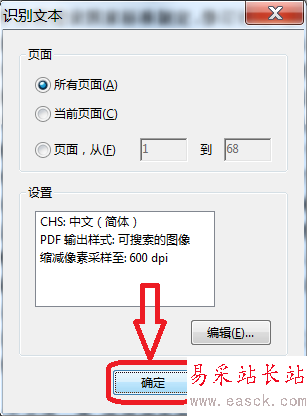
3、在彈出的“識別文本”對話框中,點擊“編輯”進行文字識別參數的設置。
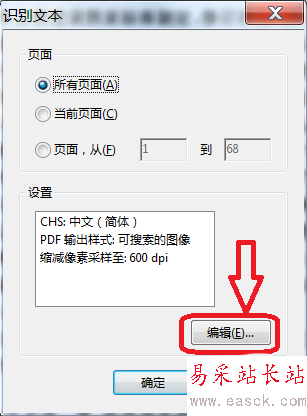
4、文字識別參數設置:OCR識別的主要語言(這里選擇簡體中文);
PDF輸出樣式:可搜索的圖像、可搜索的圖像(精確)、ClearScan(這里保持默認);
縮減像素采樣至:600、300、150、72dpi(如果要打印建議不要小于150dpi)。
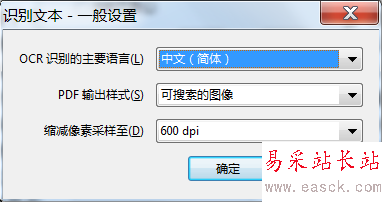
5、文字識別參數設置完成后,點擊確認開始文字識別。
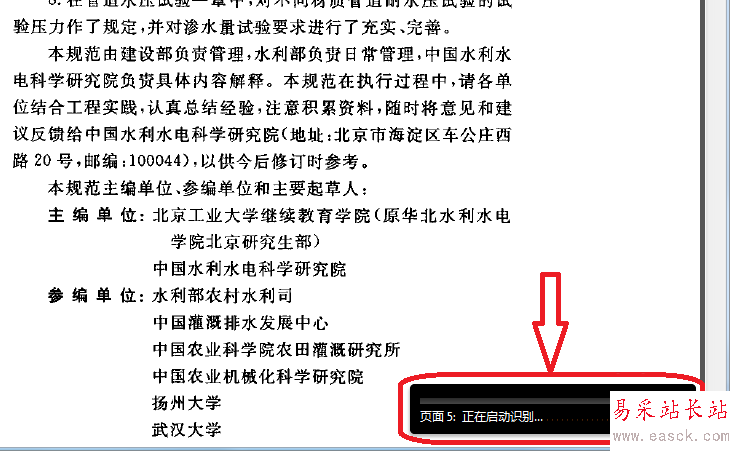
6、可以看到軟件界面底部有個文字識別進度條,如果文件較大,識別時間將會比較長,這是我們可以做些其他事情。
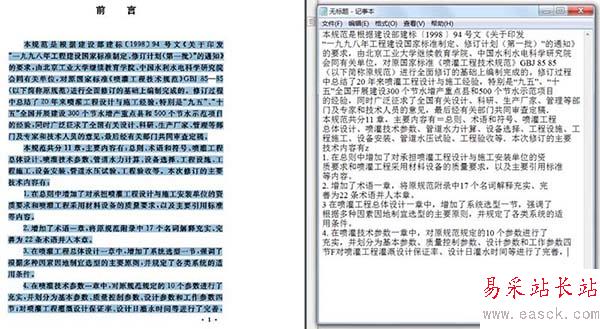
7、文字識別完成,可以看到,可以通過文本選擇工具進行選擇了。可以看出,識別準確率還是比較高的,如果需要對文字進行校對,可以查閱相關教程。
8、對比可見,添加透明文字層后,對源文件大小影響不大。

以上就是PDF掃描件制作可復制文字的雙層PDF的教程,希望大家喜歡,請繼續關注錯新站長站。
相關推薦:
Acrobat怎么給PDF添加用戶簽名?
Acrobat Pro怎么將PDF文件中的文字全部轉曲?
Acrobat2018怎么使用OCR識別掃描版PDF中的文字?
新聞熱點





疑難解答