Acrobat 2017/2018中不像之前的版本在編輯中能找到寫有OCR功能的選項,那是因為ocr識別改名為“編輯文本和圖像”了,下面我們就來看看詳細的教程。
1、打開要識別的PDF,如果該PDF沒有加密,那么點擊“編輯-編輯文本和圖像”或者在任意頁面鼠標右擊,選擇“編輯圖像”,就可以進行OCR識別了。
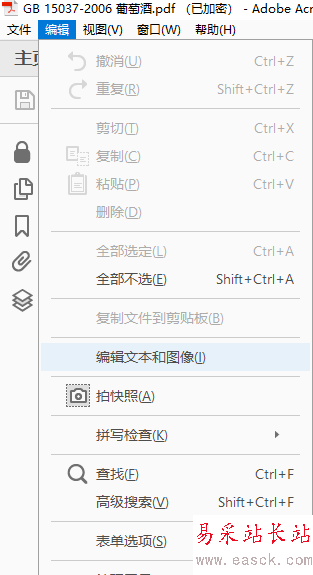

2、進行第一步之后,默認執行的單頁的識別,但是如果你要識別整個PDF文件,怎么辦?
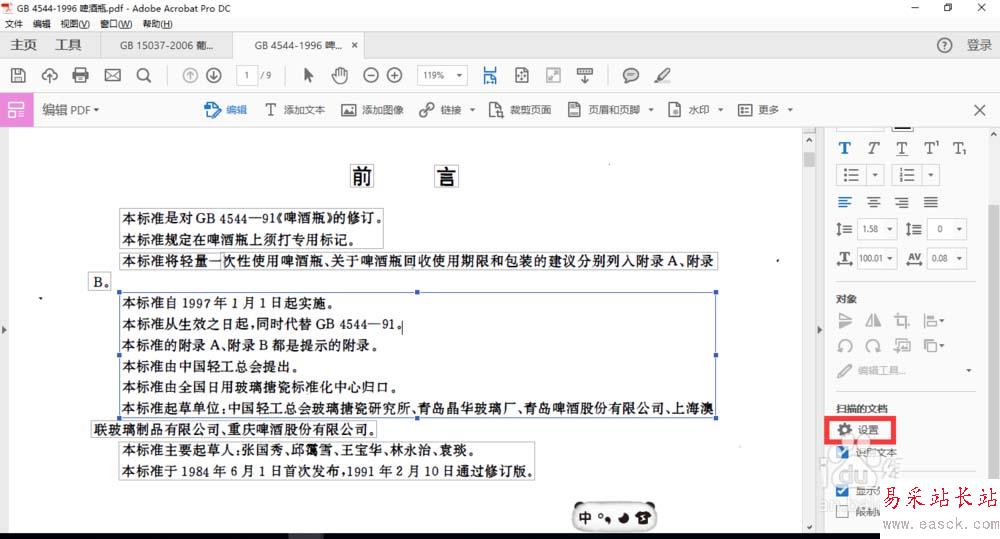
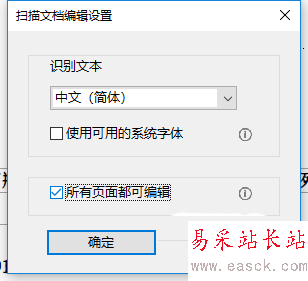
3、點擊圖中右下角掃描文檔下的“設置”,在彈出的窗口中勾選“所有頁面均可編輯”,點擊確定,再點擊編輯圖像時,就可以全篇識別了。
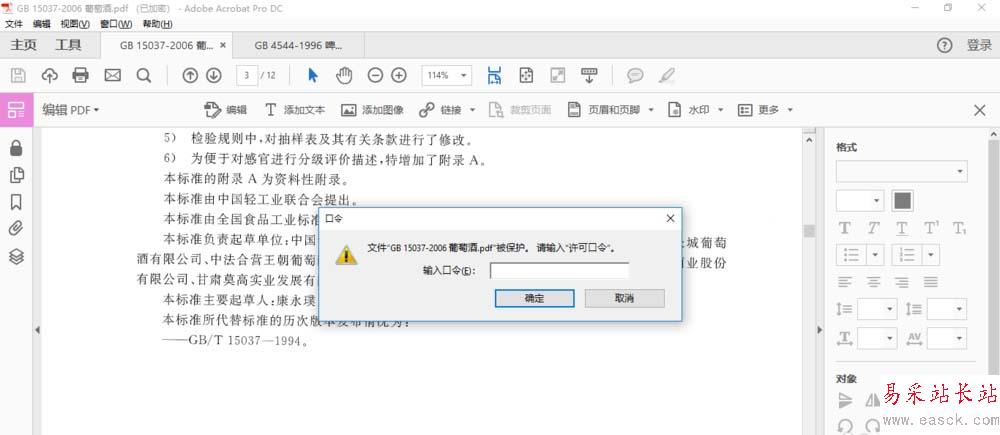
4、但是面對加密的文檔,會提示需要“輸入口令”,這個時候需要使用軟件PDFPasswordRmover,移除PDF的密碼,就可以按照上面的方法愉快的OCR識別了。有時也會出現,點了“編輯圖像”,但是未能進行OCR識別,只是把當頁識別成一整張圖片,我也用PDFPasswordRmover處理了一下,然后再進行OCR識別,就沒問題了。
以上就是Acrobat2018找不到OCR識別的原因,直接使用編輯文本和圖像也是一樣的功能,希望大家喜歡,請繼續關注錯新站長站。
相關推薦:
Acrobat編輯器怎么去除PDF簽名?
Acrobat Pro怎么將PDF文件中的文字全部轉曲?
Adobe Acrobat怎么將cmyk四色黑變成單色黑?
新聞熱點





疑難解答