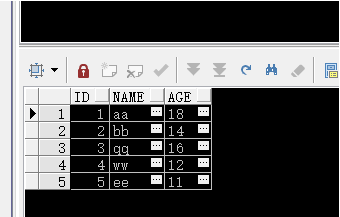
匹配語句:where coloumnvalue(列值) like 字符串 匹配常用方法: 1,字符串中有%表示另外還有零個及以上個字符 如:’%大劇院%’,表示查詢該列值中含有’大劇院’的行; 如:’%大%美’,表示查詢該列值中含有’大’且以’美’結尾的行; 2,字符串中有_表示任意單個字符串 如:’_娟’,表示查詢列值中只有兩個字符且以’娟’結尾的行 3,字符串中有[]表示匹配括號內任意一個字符串 如,’[美中蘇英]國’,表示查詢列值為美國,中國,蘇國,英國中任意一個行; 如,’%[美中蘇英]國’表示查詢列值含有美國,中國,蘇國,英國等中任意一個字段的行; 4,字符串中含有[^]表示不匹配括號內中的任意一個字符, 如,’[^趙錢孫]娟’,表示查詢列值不為’趙娟,錢娟,孫娟’中任意一個的行; 如果要查詢%,_,^,[]等特殊字符,需要利用括號[]將特殊字符括起來即可。
substr(string,position[,length]): string表示要檢索的字符串; position表示從字符串什么位置開始截取,正數表示從左邊開始數,負數表示從右邊開始數; length截取長度,負數或者零則返回null; substr(“abcdef”,1,3)=’abc’;//從左邊第一位開始往右截取3個字符 substr(“abcdef”,-1,3)=’f’;//從右邊第一位開始往右截取3個字符 substr(‘abcdef’,-4,3)=’cde’;
instr(string,substring[,position][,occurence]); string表示源字符串; substring表示要搜索的字符串; postion表示源字符串什么位置開始搜索,可選,默認為1; occurence表示匹配字符第幾次出現,可選,默認為1; 返回值為出現的位置,例如: instr(‘abcdabcd’,’ab’)=1,表示abcdabcd中第一次出現ab的位置是1; instr(‘abc/dab/cd’,’/’,1,2)=8,表示’abc/dab/cd’中從第一位開始第二次出現’/’的位置是8 instr(‘abc/dab/cd’,’/’,5,2)=0,表示’abc/dab/cd’中從第5位開始第二次出現’/’的位置是0
新聞熱點





疑難解答